Running on Kubernetes Link to heading
The ultimate goal of my ramblings about FRR and EVPN (previous posts here, here) was to extend Kubernetes node networks with EVPN, in such a way that is both dynamic and configurable in a cloud native manner.
Additionally, I wanted to setup an environment that was easy to extend and configure so I could validate all the possible variations of the configuration.
The setup Link to heading
The whole setup can be found under my personal evpn lab repository, and as before it still uses containerlab, which supports also Kind as a node type (and which is awesome!).
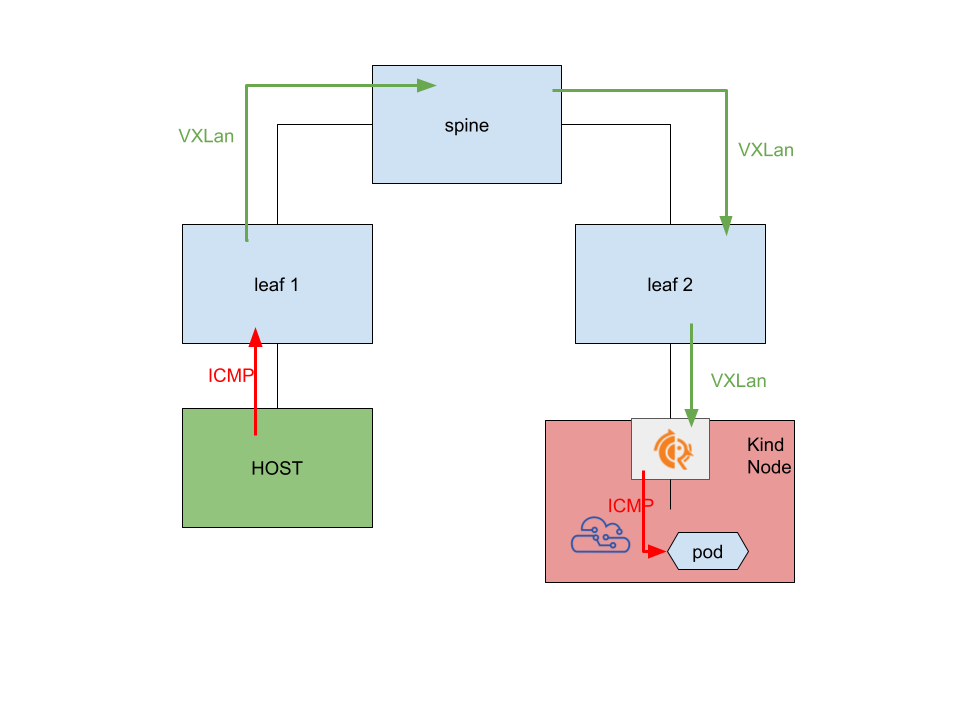
My end goal is to have something like the following picture (couldn’t go ascii this time!):
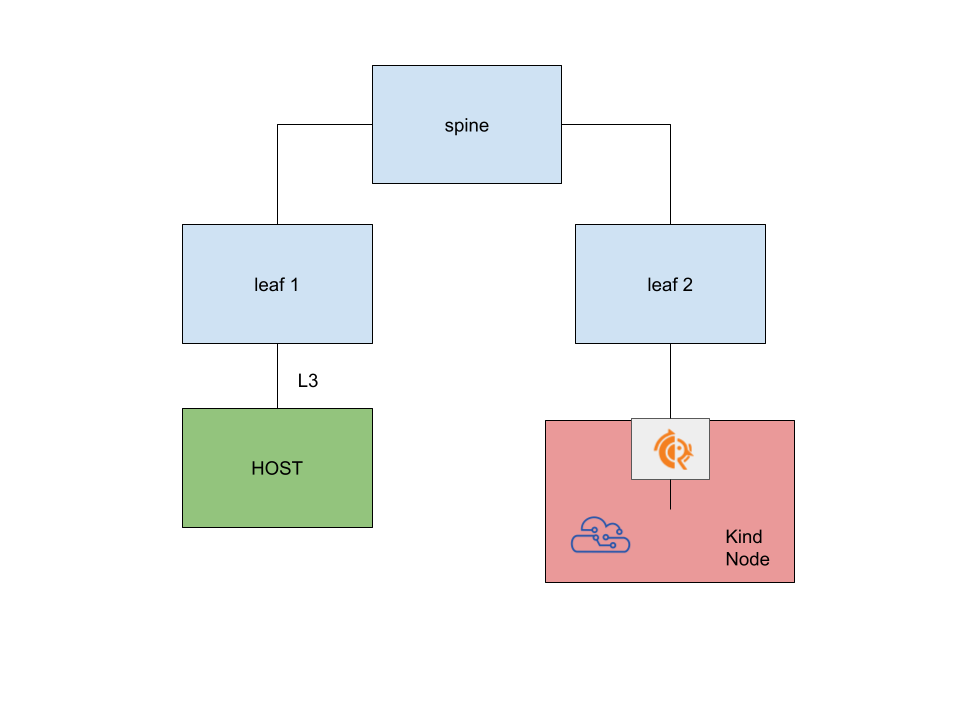
The interesing part is that, thanks to Kind, the node itself is a container which runs containers inside!
Zooming inside kind Link to heading
In this first experiment, What I want to implement inside kind is somehow complex:
- an FRR instance running inside a container, connected to the leaf
- a Veth leg (ideally, one per VRF) to connect the containerized FRR to the host
- an FRR-K8s instance running on the node, peered with the other FRR through the Veth
In this scenario:
- the leaf connected to the veth relays the type 5 routes up to the FRR instance running on Kind
- the “host” FRR instance redistributes the routes to the FRR-K8s instance via BGP
Inside the Kind node Link to heading
Let’s have a look at what’s inside the FRR container:
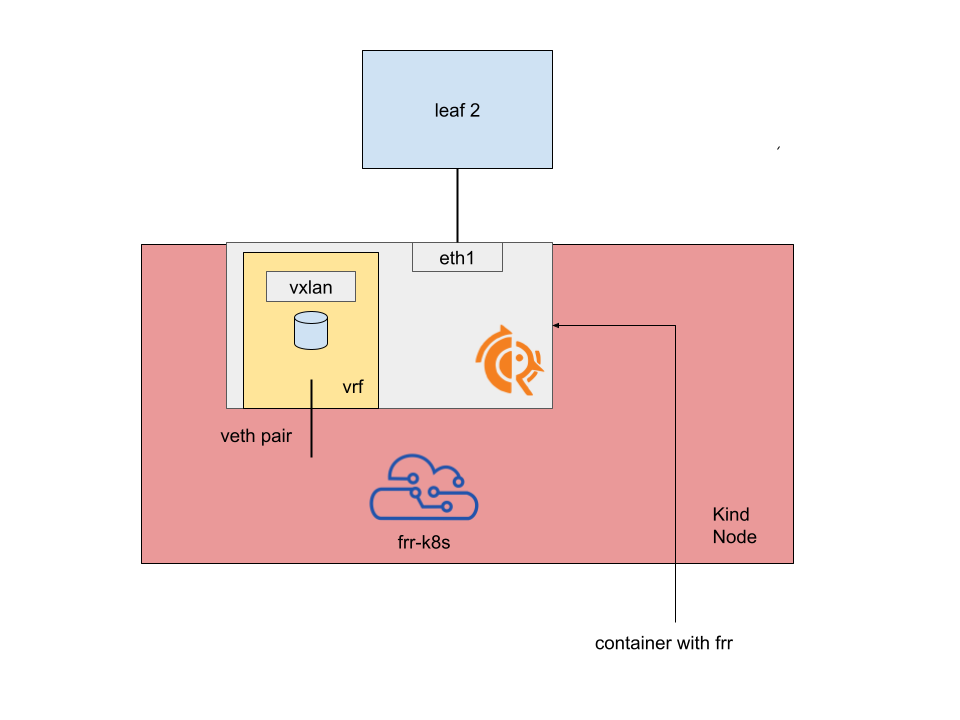
- The interface connecting the “node” to the leaf is moved inside the namespace
- A linux VRF is created and corresponds to the L3 VNI
- All the machinery required to FRR to work with EVPN is created inside the linux VRF
- A veth pair connects the container to the host
The controlplane Link to heading
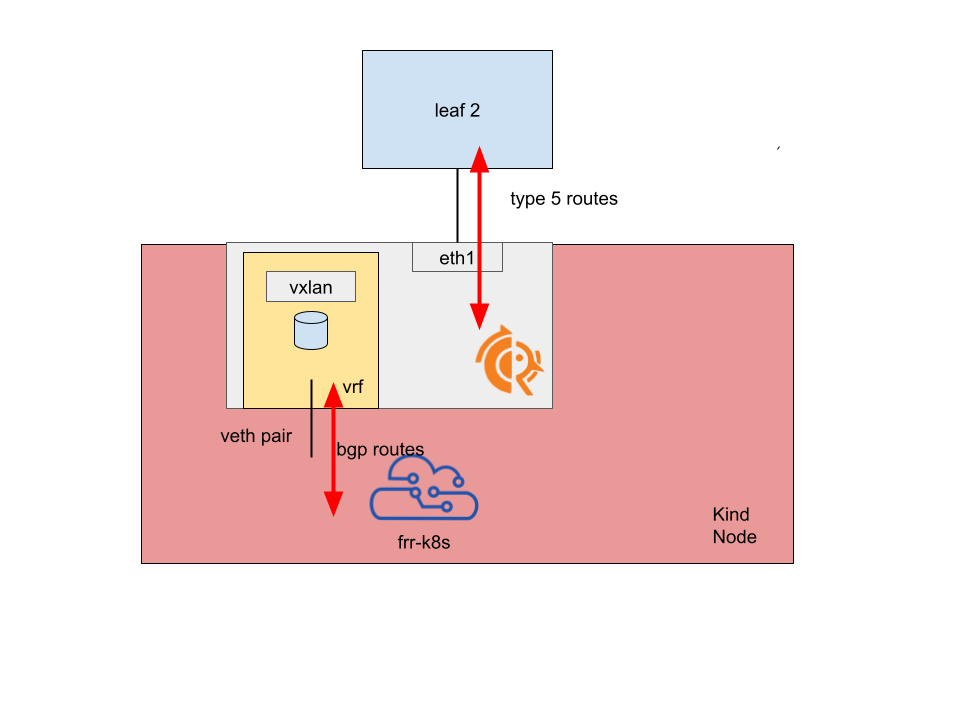
The FRR container translates BGP routes to EVPN Type 5 routes, and advertises them in both directions.
By doing this, FRR-K8s is able to advertise any IP from the node as Type5 route without bothering with linux VRFs on the host
The dataplane Link to heading
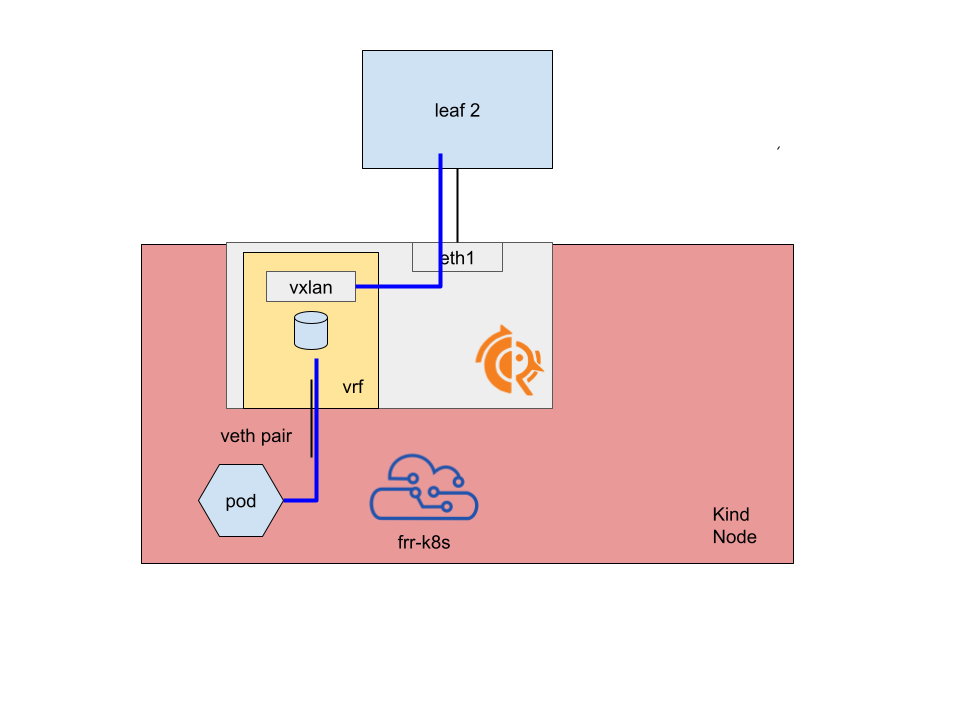
The VXLan VTEP is hosted inside the container. Packets directed to the routes adverised by the FRR container are tunneled towards the local VTEP, decapsulated from the VXLan interface and then routed accordingly to the routes (likely, the ones published by FRR-K8s).
At the same time, FRR-K8s learns about the type 5 routes advertised by the fabric, so egress traffic goes through the veth and then gets encapsulated towards the proper VTEP.
Configuring everything Link to heading
The topology Link to heading
The topology is quite similar to the one described before in the previous article about L3-EVPN. The main difference being, instead of
a host connected to the leaf2, here we have the node of a cluster:
k0:
kind: k8s-kind
image: kindwithdocker:v1.29.2
k0-control-plane:
kind: ext-container
binds:
- kind/setup.sh:/setup.sh
links:
- endpoints: ["leaf1:eth1", "spine:eth1"]
- endpoints: ["leaf2:eth1", "spine:eth2"]
- endpoints: ["HOST1:eth1", "leaf1:eth2"]
- endpoints: ["k0-control-plane:eth1", "leaf2:eth2"]
One extra thing to notice is that, since I needed to start the FRR container from the host, I am providing a custom image with docker already deployed.
Then, a link is defined between leaf2 and the k0-control-plane node.
- endpoints: ["k0-control-plane:eth1", "leaf2:eth2"]
The FRR Configuration of the namespaced FRR Link to heading
I won’t share the details of the setup of the container:
- moving the interface to the container’s namespace
- creating the veth and putting one leg inside the container
- setting up routes
- setting up the VRFs, bridge and VXLans required to FRR to make EVPN to work
They are available in the setup.sh file related to the node setup and the setup.sh file related to the container setup.
What might be interesting is the FRR configuration of the namespaced FRR:
The section related to the default VRF contains the details of the underlay. It establishes a session with leaf2, advertises the local VTEP ip (100.65.0.2/32)
via BGP, and enables the l2vpn address-family:
address-family ipv4 unicast
neighbor 192.168.11.2 activate
network 100.65.0.2/32
exit-address-family
address-family l2vpn evpn
neighbor 192.168.11.2 activate
neighbor 192.168.11.2 allowas-in origin
advertise-all-vni
advertise-svi-ip
exit-address-family
On the VRF side, we advertise the unicast ipv4 / ipv6 addresses to the evpn address family:
router bgp 64512 vrf red
address-family l2vpn evpn
advertise ipv4 unicast
advertise ipv6 unicast
exit-address-family
but most importantly, we also establish a BGP session with the local FRR-K8s container from the
red VRF, and we redistribute the routes from / to it via BGP:
router bgp 64512 vrf red
neighbor 192.169.10.0 remote-as 64515
!
address-family ipv4 unicast
neighbor 192.169.10.0 activate
neighbor 192.169.10.0 activate
neighbor 192.169.10.0 route-map allowall in
neighbor 192.169.10.0 route-map allowall out
exit-address-family
!
address-family l2vpn evpn
advertise ipv4 unicast
advertise ipv6 unicast
exit-address-family
Lastly, the FRR-K8s configuration is also straightforward, establishing a session with the containerized FRR, receiving prefixes to it and advertising the pod CIDR:
apiVersion: frrk8s.metallb.io/v1beta1
kind: FRRConfiguration
metadata:
name: test
namespace: frr-k8s-system
spec:
bgp:
routers:
- asn: 64515
neighbors:
- address: 192.169.10.1
asn: 64512
toReceive:
allowed:
mode: all
toAdvertise:
allowed:
mode: all
prefixes:
- 10.244.0.0/24
Does it work? Link to heading
Getting back to the high level picture, the goal here is to have a pod reach HOST and viceversa:
Checking the routes on leaf1 Link to heading
docker exec -it clab-kind-leaf1 vtysh -c "show bgp l2vpn evpn"
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 192.169.10.1:2
*> [5]:[0]:[24]:[10.244.0.0]
100.65.0.2 0 64612 64512 64514 64515 i
RT:64512:100 ET:8 Rmac:aa:bb:cc:00:00:66
Displayed 2 out of 2 total prefixes
So, leaf1 learned about the pod CIDR advertised by FRR-K8s!
Let’s check on the other side, inside FRR-K8s first:
k0-control-plane# show bgp ipv4
BGP table version is 2, local router ID is 192.169.10.0, vrf id 0
Network Next Hop Metric LocPrf Weight Path
*> 10.244.0.0/24 0.0.0.0 0 32768 i
*> 192.168.10.0/24 192.169.10.1 0 64512 64512 64612 64512 ?
Displayed 2 routes and 2 total paths
FRR-K8s learned the route towards HOST1 via the veth leg connecting it to the containerized FRR.
Lastly, let’s check what we have in the containerized FRR, acting as Leaf in this case:
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 192.168.10.2:2
*> [5]:[0]:[24]:[192.168.10.0]
100.64.0.1 0 64512 64612 64512 ?
RT:64512:100 ET:8 Rmac:aa:bb:cc:00:00:65
Route Distinguisher: 192.169.10.1:2
*> [5]:[0]:[24]:[10.244.0.0]
100.65.0.2 0 0 64515 i
ET:8 RT:64512:100 Rmac:aa:bb:cc:00:00:66
Displayed 2 out of 2 total prefixes
Here we have the HOST1 network advertised with the leaf1’s VTEP IP and the pod network CIDR advertised with the local VTEP.
Does it really work? Link to heading
Let’s try:
docker exec -it clab-kind-HOST1 ping 10.244.0.6
PING 10.244.0.6 (10.244.0.6) 56(84) bytes of data.
64 bytes from 10.244.0.6: icmp_seq=1 ttl=61 time=0.148 ms
64 bytes from 10.244.0.6: icmp_seq=2 ttl=61 time=0.090 ms
^C
--- 10.244.0.6 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1052ms
rtt min/avg/max/mdev = 0.090/0.119/0.148/0.029 ms
Checking on leaf2 we see that both the request and the reply are encapsulated, which makes sense as the tunneling happens locally to the node.
sudo ip netns exec clab-kind-leaf2 tcpdump -nn -i any
tcpdump: data link type LINUX_SLL2
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
17:24:55.850570 eth1 In IP 100.64.0.1.52099 > 100.65.0.2.4789: VXLAN, flags [I] (0x08), vni 100
IP 192.168.10.1 > 10.244.0.6: ICMP echo request, id 4, seq 1, length 64
17:24:55.850576 eth2 Out IP 100.64.0.1.52099 > 100.65.0.2.4789: VXLAN, flags [I] (0x08), vni 100
IP 192.168.10.1 > 10.244.0.6: ICMP echo request, id 4, seq 1, length 64
Wrapping Up Link to heading
The path of this packet is quite complex, and I never felt so happy to see a ping work :-)
Host -> Leaf1 -> VXLan encapsulation -> Spine -> Leaf2 -> FRRContainer -> VXLan decapsulation -> Veth -> Node -> Pod
This was just a POC to showcase how to handle a PE Router of some sort on a kubernetes node, and accessing the EVPN network through a veth leg can get rid of the complications introduced by having several Linux VRFs on the host.
I will probably experiment again a solution where everything is shared and handled by the same FRR instance on the node.
Also, to make things more complex, there is already an example of connecting the cluster to multiple EVPN / VXLans on my evpn lab github repository.