Following up Link to heading
As I wrote in my last post, one thing I have been experimenting with is to run EVPN termination inside a Kubernetes node. I demonstrated how to achieve it by running a container on the host as per the following image:
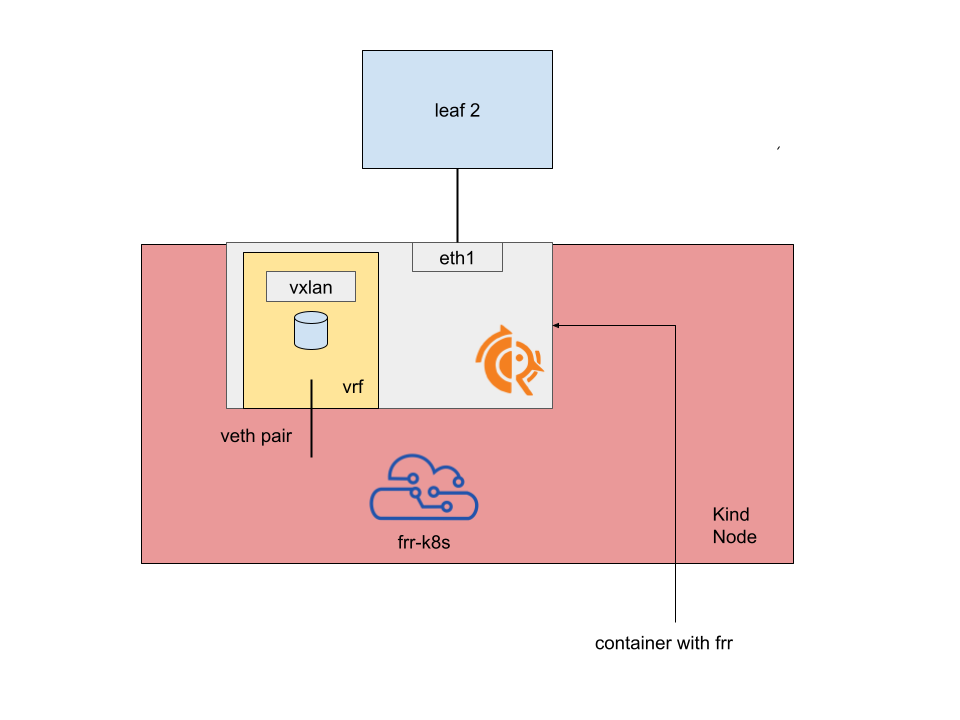
This clearly brings some deployment and lifecycle challenges that include:
- running the container and keeping it running
- updating it
- configuring it
All these things are clearly solved by Kubernetes itself, so why not trying to run the whole ensamble inside pods? This may sounds a bit crazy, as it involves dynamically moving interfaces into a different namespace and creating veths and all the rest it was previously described.
The architecture Link to heading
The architecture is a bit as follows:
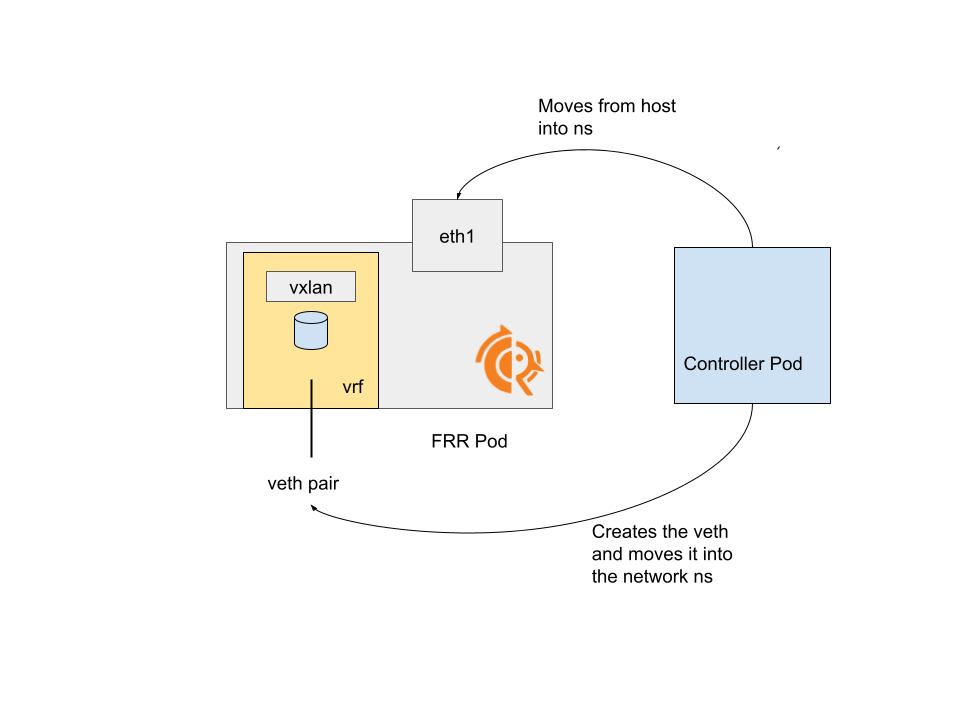
A pod running FRR Link to heading
This is the same as the container showed in the previous examples, just running inside a regular pod (which means, running in a separate network namespace).
The pod definition can be found under my evpn lab repo.
A powered up host-networked pod (the controller) Link to heading
The pod definition can be found under my evpn lab repo.
This pod is able to interact with the host network, in particular for:
- Creating the Veth pair and moving one end inside the FRR pod
- Moving the interface used for the underlay network inside the FRR pod
Knowing which namespace to move the interfaces into Link to heading
In order to know what is the network namespace of the FRR pod, some crictl commands are performed, but it’s quite straightforward (or it is now, after sweating a lot on it :-) ):
POD_ID=$(crictl -r /var/run/containerd/containerd.sock pods --name=frr --namespace=frrtest -q --no-trunc) NSPATH=$(crictl -r /var/run/containerd/containerd.sock inspectp ${POD_ID} | jq -r '.info.runtimeSpec.linux.namespaces[] |select(.type=="network") | .path')
NETNS=$(basename $NSPATH)
Note that this assumes both the containerd socket and the host namespaces to be mounted inside the container:
volumeMounts:
- mountPath: /run/containerd/containerd.sock
name: varrun
subPath: containerd.sock
- mountPath: /run/netns
name: runns
mountPropagation: HostToContainer
Configuring the whole thing Link to heading
Configuring the interfaces Link to heading
The configuration (and the orchestration) is deferred to the external execution of a script on each container, in the base setup.sh file.
We run commands from the controller first, from its setup.sh file, where we:
- find the target network namespace
- create the veth pair and move one end into the other pod
- move the underlay interface into the other pod
Then, we configure frr with the corresponding setup.sh script, where we configure the host network to make EVPN work, including:
- creating a linux VRF
- creating a VXLan interface and a linux bridge
- adding a VTEP ip to the loopback interface
The FRR configuration Link to heading
The FRR configuration is provided as a configmap and resembles what was described previously, including:
- an underlay session with the leaf on the default VRF, where we advertise L3VPN routes
- a BGP session with FRR-K8s via the added veth leg
I won’t enter into the details of how the packets are flowing as it’s covered in detail in my previous post, and here I am doing the same thing, but with pods instead of host processes / containers. The whole flow is as before, just with these pods around:
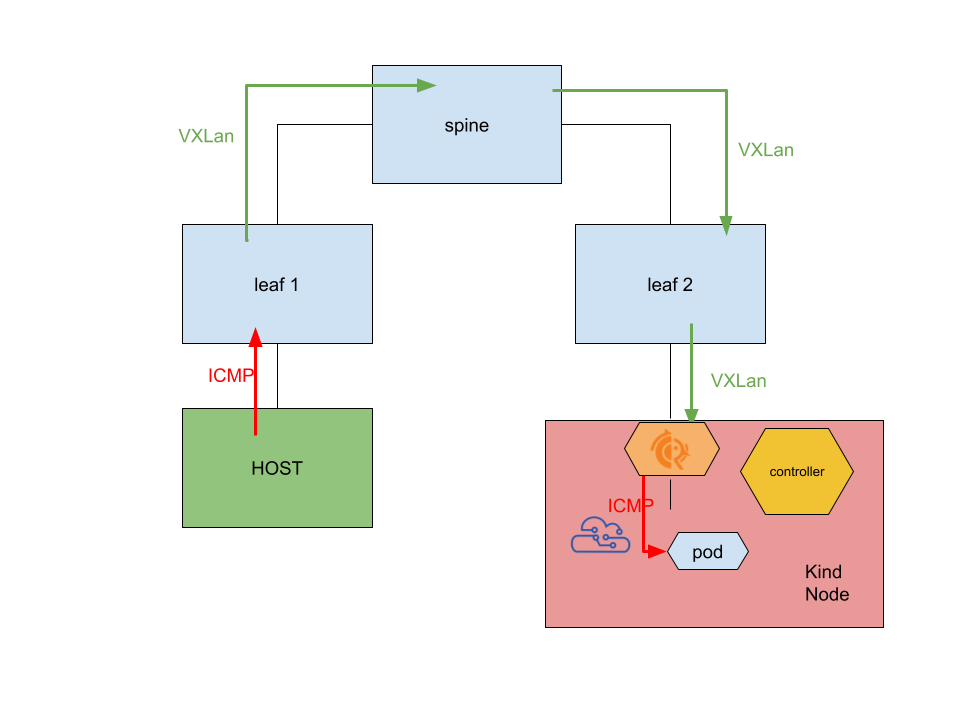
Limitations Link to heading
We are giving up one host interface Link to heading
This was true also with the previous iterations, but it’s important to notice that each node is expected to have one other running interface used for example to reach the API server in order to fetch the various resources.
I wrote a variant of this lab where a VLan interface is created out of the “physical” one and used for the underlay connection.
We can’t use EVPN for all the types of traffic Link to heading
Because of the chicken - egg problem mentioned above, if we make a controller out of this, we can’t delegate all the type of traffic as EVPN traffic:
- the controller will have to read the configuration in order to enable the EVPN / vxlan tunnel
- the node needs EVPN to read the configuration
In any case, this is a good first step that would enable extending the Kubernetes node network by just throwing the usual bunch of yamls against it :-)
I will write a new blogpost in the near future on how we can have this whole thing deployed before the kubelet starts.
It really works Link to heading
As per all the previous examples, I am leveraing the super handy containerlab and by running the setup.sh script from my repo you’ll get what’s described above.
The usual ping the pod from the remote host works fine because the pod CIDR is carries as a L3EVPN route to the other leaf:
docker exec -it clab-kindpods-HOST1 ping 10.244.0.6
PING 10.244.0.6 (10.244.0.6) 56(84) bytes of data.
64 bytes from 10.244.0.6: icmp_seq=1 ttl=61 time=0.649 ms
64 bytes from 10.244.0.6: icmp_seq=2 ttl=61 time=0.378 ms
^C
--- 10.244.0.6 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1037ms
rtt min/avg/max/mdev = 0.378/0.513/0.649/0.135 ms
And by tcpdumping, we ensure the packet is really being encapsulated via VXLan and is not taking some rougue route:
tcpdump -i eth2 -nn
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth2, link-type EN10MB (Ethernet), snapshot length 262144 bytes
11:20:26.825604 IP 100.64.0.1.40319 > 100.65.0.2.4789: VXLAN, flags [I] (0x08), vni 100
IP 192.168.10.1 > 10.244.0.6: ICMP echo request, id 2, seq 33, length 64
11:20:26.825724 IP 100.65.0.2.40319 > 100.64.0.1.4789: VXLAN, flags [I] (0x08), vni 100
IP 10.244.0.6 > 192.168.10.1: ICMP echo reply, id 2, seq 33, length 64
To sum up Link to heading
Making a kubernetes controller out of this will enable some fancy networking capabilities for our clusters, such as joining EVPN networks in a dynamic (and crd controlled!) fashion.
Let’s see what’s at the end of this rabbit hole, as every time it reveals itself to be deeper!