Quick Recap Link to heading
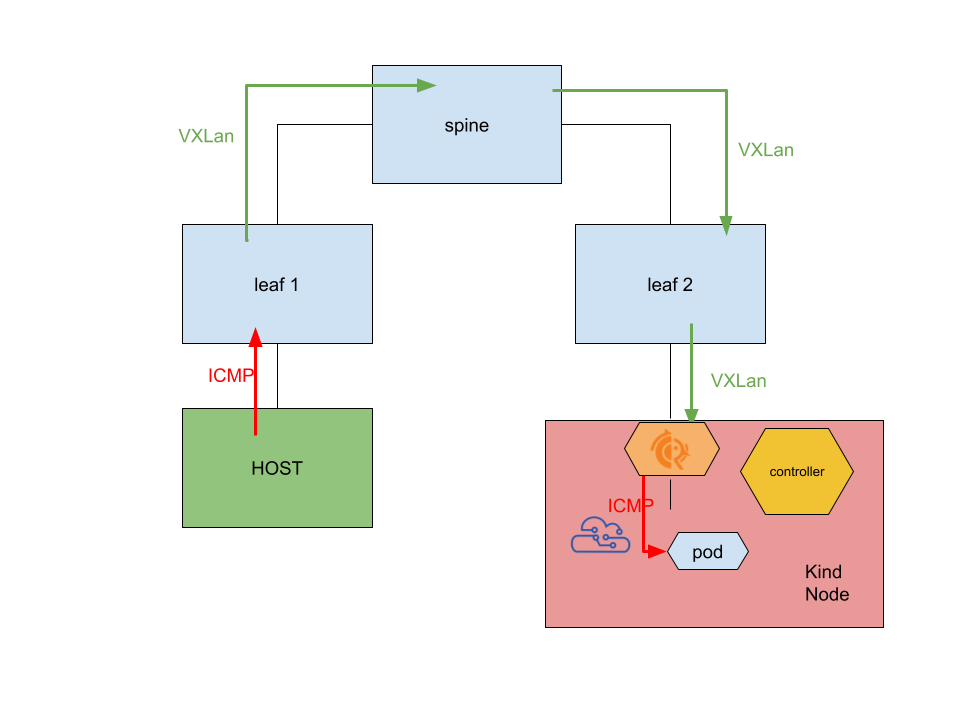
This is a follow up to my lengthy EVPN series. In my last post I demonstrated how I managed to have EVPN termination inside Kubernetes nodes, hosting FRR inside a regular network-namespaced pod interacting with the host via BGP through veth pairs.
Overcoming the limitations Link to heading
I also described how running inside a pod is limiting this architecture and prototype to serve the node’s main interface, because of the chicken egg-y issue of needing the underlay network to allow each node to reach the API server, while at the same time the configuration required to establish the underlay must be retrieved from the API server itself.
In this post, I am going to take a step further by running the two pods as podman systemd units. The architecture is more or less the same, with the biggest difference being of having podman pods running as systemd units.
Rethinking the architecture Link to heading
Before jumping into how to run podman pods, I’ll describe how this was a chance to rethink the architecture of the various actors, making the FRR container dumber and delegating all the network configuration logic to the controller
container.
The previous version Link to heading
In previous iterations
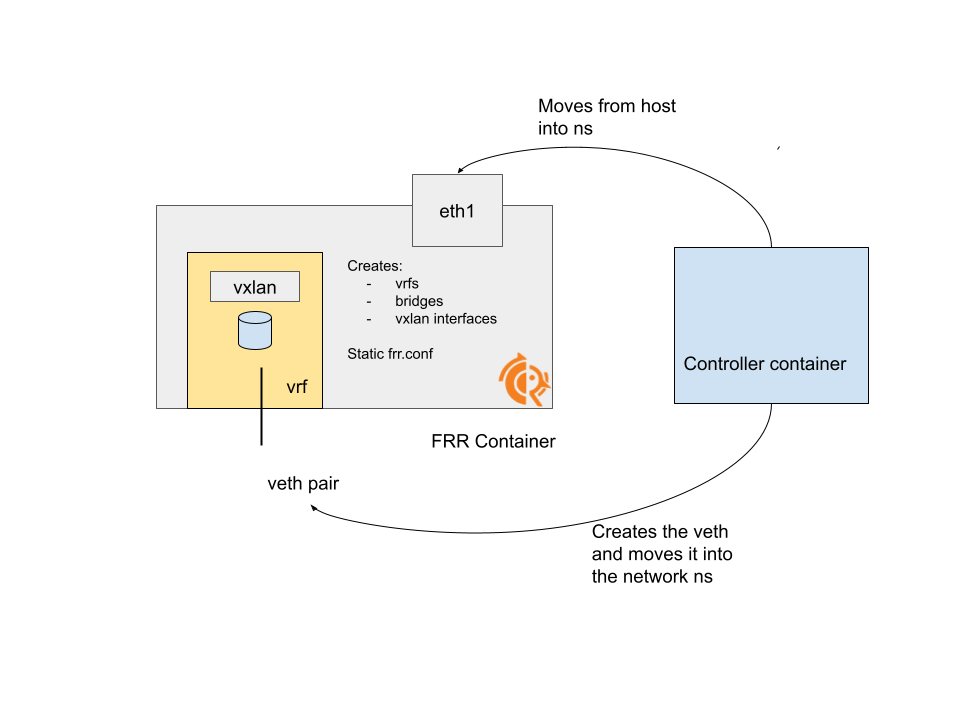
- we had a static
frr.confconfiguration, tailored to the poc and read by FRR at startup and provided to the pod as a ConfigMap - the controller pod was responsible of moving the interface to be used for the underlay network, to create the veth pairs and to move one end inside the container
- the FRR pod was responsible of configuring the network side required to make FRR happy and have EVPN working (see the frr pod setup.sh script for example)
Note also that this last step assumes the veth leg and the main interface to be available, requiring some kind of orchestration between the two separate components (because the controller must have done its part before the veth leg and the main interface can be configured accordingly).
The new version Link to heading
I wanted to evolve the components in a cleaner way (because the goal is still to automate all this logic :-)), so it felt better and less racy to have one single component in charge of all the configuration.
In this new iteration:
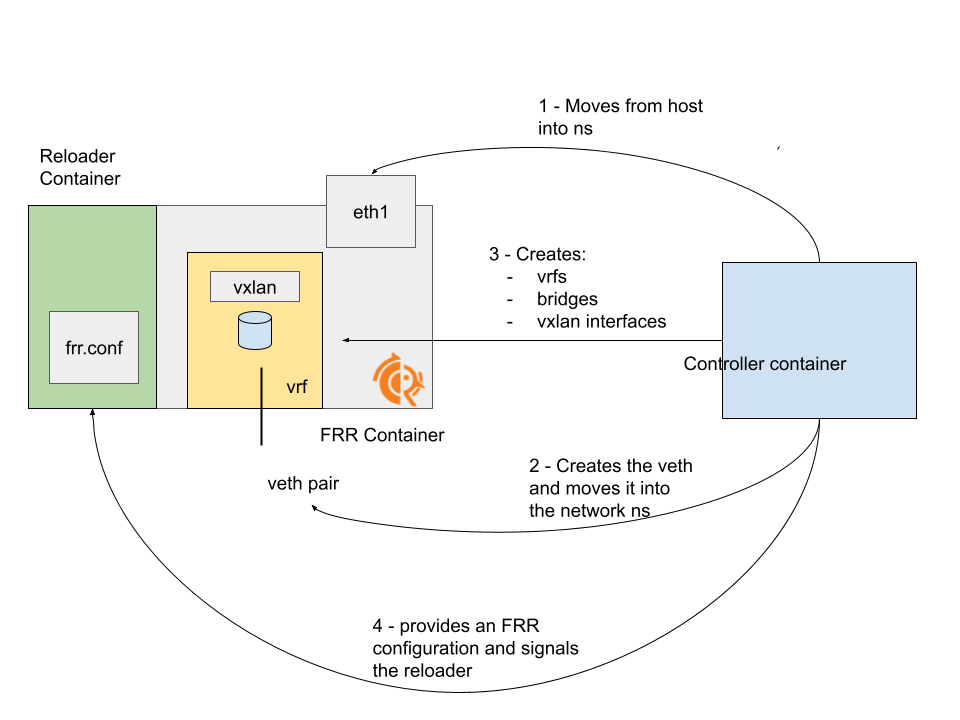
- the FRR container is responsible only for the routing part
- a sidecar container is listening to a signal and reload the FRR configuration (following the same pattern we implemented in MetalLB and FRR-K8s)
- all the logic happens in the
controllercontainer:- creating and moving the veths into the FRR namespace
- moving the interface used for the underlay into the FRR namespace
- creating the bridge, the VXLan interfaces and assigning a VTEP IP in the FRR namespace
- moving the FRR configuration to a shared volume
- sending a signal to the reloader sidecar
By doing this, we can run sequentially all the actions required to have the same setup shown in the previous posts, without risking to have races.
Emulating with scripts Link to heading
I managed to have a decent prototype of the described behaviour by:
- starting the FRR container with an empty
frr.conf, providing the finalfrr.confto the controller and then copying it - having a script listening for connections and reloading
- having the controller running a bunch of
ip netns execcommands to configure the interfaces in the FRR namespace
Running Podman pods as systemd units Link to heading
Now that we know the moving parts, let’s deploy them as podman pods / systemd units.
What we need is:
- a regular
FRRpod - a
network=host, lot of capabilitiescontrollerpod - shared folders (to copy the frr configuration)
- a way to let the
controllerpod know the network namespace of thefrrpod
Following this post, the steps are:
Create the pod:
podman pod create --share=+pid --name=frrpod -p 7080:7080
Create the containers belonging to the pod:
podman create --pod=frrpod --pidfile=/root/frr/frrpid --name=frr --cap-add=CAP_NET_BIND_SERVICE,CAP_NET_ADMIN,CAP_NET_RAW,CAP_SYS_ADMIN -v=/root/frr:/etc/frr -v=varfrr:/var/run/frr:Z -t quay.io/frrouting/frr:10.0
.1 /etc/frr/start.sh
podman create --pod=frrpod --name=reloader -v=/root/frr:/etc/frr -v=varfrr:/var/run/frr:Z --entrypoint=/etc/frr/reloader.sh -t quay.io/frrouting/frr:10.0.1
Generate the corresponding systemd units:
podman generate systemd --new --files --name frrpod
Starting the systemd unit:
systemctl start pod-controllerpod
By doing this, we give up the configurability via CRD offered by Kubernetes, but we gain independence from a kubernetes node lifecycle. In particular, this systemd units can be enabled and those containers can be started as soon as a node starts.
First hurdle: finding the right network namespace Link to heading
This is something that kept me busy for a bit, because here we can’t use the CRI API to find the network namespace of the pod, simply because these containers are not running as pods.
The solution I found was to tell podman to create a pid file for the FRR container
podman create --pod=frrpod --pidfile=/root/frr/frrpid
and then to use that from the controller to find the target namespace
FRRPID=$(cat /etc/frr/frrpid)
NETNS=$(ip netns identify $FRRPID)
With that, I was able to consume the target namespace and provide the configuration required.
Seeing it in action with Podman, ContainerLab and Kind Link to heading
Surprisingly, it works! I have an (almost) working prototype under my evpn lab repo, where I was able to test the topology described in the previous post with ContainerLab, Kind and podman running inside the Kind node (a docker container !!!!).
The ContainerLab setup looks like this
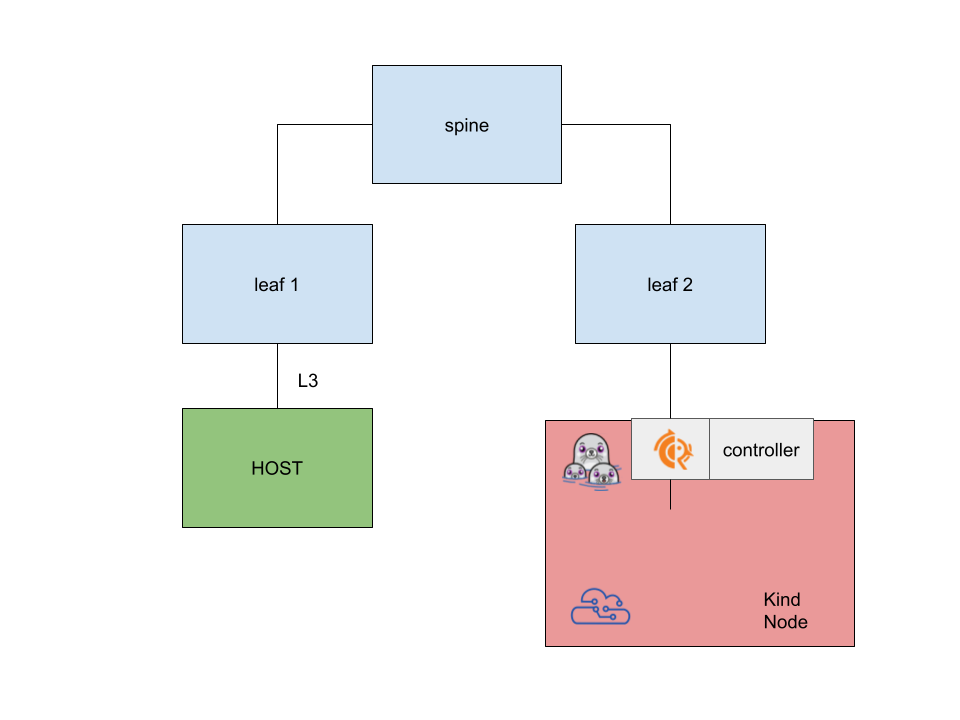
In order to start it, it is enough to run the setup.sh file.
It will:
- start ContainerLab and kind
- deploy frr-k8s
- configure the podman pods as systemd units (entry point here)
Testing it Link to heading
The way the routes are exchanged are no different from what I described in my previous post. The ping test works here too!
docker exec -it clab-kindpods-HOST1 bash
bash-5.1# ping 10.244.0.6
PING 10.244.0.6 (10.244.0.6) 56(84) bytes of data.
64 bytes from 10.244.0.6: icmp_seq=1 ttl=61 time=0.171 ms
64 bytes from 10.244.0.6: icmp_seq=2 ttl=61 time=0.070 ms
Wrapping up Link to heading
Having the flexibility of Kubernetes for handling the lifecycle of our EVPN pod is great, but comes with a limitation, as I wrote in the beginning. Having it running as a systemd unit allows to provide connectivity that goes beyond extra networks.
Additionally, we revisited the architecture and how the components interact, providing a better separation of responsibilities.