This is the second part of my “writing a kubernetes controller” blogpost.
Here, I will explain how to put what was explained int the first part in go code.
Setting the informer and the workqueue Link to heading
This is the first step, where you listen for events and send them to the consumers via the workqueue:
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
informer := kubeInformerFactory.Core().V1().Pods()
informer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
pod := obj.(*v1.Pod)
key, _ = cache.MetaNamespaceKeyFunc(obj)
workqueue.Add(key)
},
...
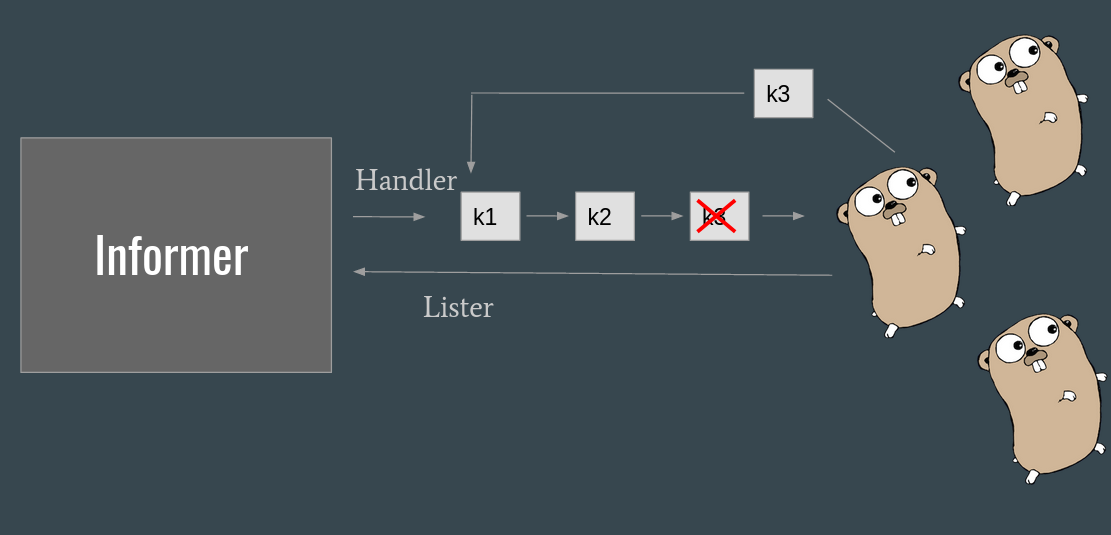
One important thing to note is the fact that we extract the key of the object we received (using cache.MetaNamespaceKeyFunc) and we put it into the queue.
This is because we want to handle the fresh-est image when the event reaches the worker (remember edge triggered / level driven from part 1?).
Another important thing to take into account is that we want to make sure that we are spinning all the consumers only when the cache of the informer is full and well aligned. This, again, is because the cache plays an important role in consuming the data on the worker side.
To ensure that, what we need to do is:
cache.WaitForCacheSync(stopCh, informer.Informer().HasSynced)
// spin up workers
On the worker side Link to heading
obj, shutdown := c.workqueue.Get() // 1
if shutdown {
return false
}
defer workqueue.Done(obj) // 2
if key, ok := obj.(string); !ok { // 3
// should never happen
}
if err := handle(key); (err != nil && isRecoverable(err)) { // 4
workqueue.AddRateLimited(key) // 5
return fmt.Errorf(“Help”)
}
c.workqueue.Forget(obj) // 6
return nil
Here’s what we do:
- we fetch the object from the queue (1)
- we tell the queue when we are done handling the event (2)
- we convert the event to a string (the key of the event) (3)
- we handle it (4)
- if a recoverable error happens, we add the event back to the queue (5)
- if everything goes fine, we tell the queue to forget about the item (6)
This is strongly influenced by the behaviour of the ratelimiting workqueue.
When we put a key into the queue, any other addition of the key to the queue will override the current one. This means, only one instance of the same key can be in the queue at the same time. The only caveat is, a key is inserted when a worker is handling the same key. This is the exact reason why we need to call workqueue.Done. Only after that, the key will be re-queued and available for being handled.
Another couple of calls are related to the retry mechanism. We said that in the kubernetes world failures are normal and we must have a consistent way to retry, and that’s what workqueue.AddRateLimited does. Basically, the key is sent back to the queue and re-submitted after the retry policy implemented by the queue (the default one is a variation of exponential backoff).
In this way, our reconciliation loop will receive the key again, and it will hopefully be able to handle it without failures.
This has two big implications:
- our reconciliation loop should not do any active form of retry. It should just send the event back to the queue and wait for it to come again.
- it’s up to the business logic to choose what errors are recoverable and what not. Adding a non recoverable error to the queue (i.e. one event that will always fail) will result in a continuous reconciliation loop (even though, with the backoff policy).
Finally, if we handle the key successfully, we call Forget and the queue will forget about the item.
When we handle the key, we need to retrieve the full object from the cache:
ns, name, _ := cache.SplitMetaNamespaceKey(key)
pod, err := informer.Lister().Pods(namespace).Get(name)
….
Please note here that the pod we are fetching from the cache may be more recent than the image that triggered the event.
// todo put a drawing here
This happens in a scenario where the consumer is slow (or busy consuming other events) while the same pod object has a lot of variations in the meanwhile.
From the queue perspective, the one and only key is in flight, and the image is updated in the cache. When the key finally reaches the consumer, the consumer (a goroutine) fetches the freshest image from the cache.